
如何设计动态(不定)字段的产品数据库表?
浏览量:819
项目组会议上讨论的关于不定字段数目的数据库表问题并没有结果,今天继续分析之后发现问题可能还更大。当时讨论的结果是可能采用四种技术:
动态增加数据库表字段
预留足够的空白字段,运行时作动态影射
用xml格式保存在单字段里
改列为行,用另外一个表存放定制字段
【一】
现在我们来分析一下四种技术的优劣,不过首先可以排除的是第一点动态增加字段的方法,因为在实际操作时候几乎是不可能的(sqlserver太慢,oracle索性不支持),基本可以不讨论就排除。剩下后三点。
【二】
先来讨论预留空白字段的方法,基本原理就是在数据库表设计的时候加入一些多余的字段,看下面的代码:
CREATE
}
然后看实际运行时候的需要,动态分配字段给系统使用,也许需要一个这样的结构来描述分配情况:
public class Available
{
}
也许某一时刻的数据状况是这样的: CurrentUnusedFieldNumber
现在的问题是如果要配合Hibernate,如何来处理?以上段的数据使用状况为例子,如果我们的类定义是这样:
public class Entity01
{
}
也许只需要修改一下xxx.hbm.xml,把 SomeId 和 field0 做成对应就ok了。但是在运行时我们怎么知道会有这样的类定义?除非我们做动态代码生成,自动编译也许可以,但是问题也许就到其他方面去了;如果我们不用动态定义,那么类就只能是这样:
public class Entity01
{
}
使用的时候,用 entity01.ExtraFieldAndValues.setValue("AnyName", "boss") 的方式来引用,也许这样是修改最少的了,但是问题是Hibernate不支持这样的方法。
【三】
再来讨论单字段存储的方法,我们使用这样的数据库表定义
CREATE TABLE Sample
(
)
然后对应这样的类定义
public class Entity01
{
}
我们的代码就可以这样使用:string id = entity01.ExtraNameAndValueFromXml
是不是折衷一下,把两种方法的优点和起来?问题有来了:怎么保持两者之间数据的同步?难道要我们用存储过程去解析xml内容?
所以,一个两难的问题,需要我们认真去解决。我们通过认真的需求分析,也许可以减少可变字段的数量,但是只要有一个可变字段或者可变的可能性存在,我们始终要去解决这个两难的问题。
期待继续讨论。
【四】
还有一种方法就是改列为行,用另外一个表存放扩展字段,定义可以如下:
CREATE TABLE SampleFields
(
)
其中idSample关联到Sample表的id字段(我没有写出来)。这样的话,Hibernate很容易支持,也可以支持Sql的查询,而且可以支持把内容放到Hashtable中去,看起来是目前最好的方式了。但是在大容量数据的时候,SampleFields表的数据会是主表数据量的N倍(看定制的字段数目多少而定),同样存在有很严重的性能问题。
哪位高人还能再给一个方案?
---------------------------------------------------------------------------------------------------------------------------------
--------2005-7-22新增-----------
很多朋友给出了很好的建议,其中蛙蛙池塘
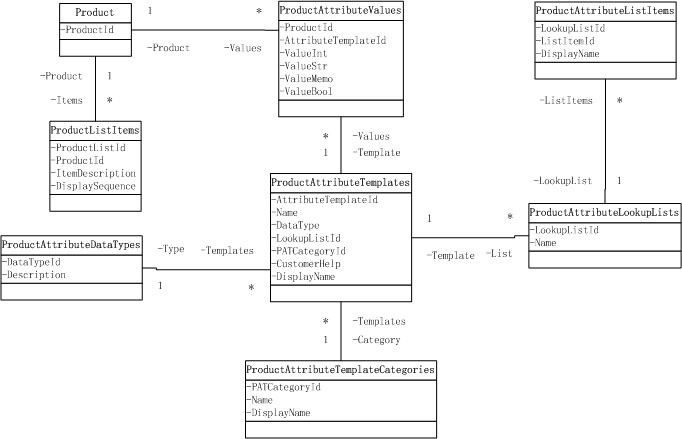
图所表示的内容简单来说是这样:
1。一个很宽的表ProductAttributeValues,包含用到的几乎所有可能的类型的值,但是每次只能用一个类型的值
2。将可变的列转为行,存放到上表中
3。为了存放类型定义和一些下拉列表的内容,设计了ProductAttributeTemplate
4。ProductListItems中存放Product中所有项的说明和顺序。
这种思路其实就是把产品的“知识级”(设计模式用语)和“操作级”都表现出来了,如果要划分,则图的左上角三个表属于“操作级”,其余的属于“知识级”。wljcan
怡红公子
不过我现在觉得xml字段还是要的,作为辅助存储手段,因为毕竟未来查询起来可能会更方便些,然后结合“观察模式”也就是类似上图的方法作为主要的存储手段,虽然有一些冗余,结合我的使用 NVelocity 解析 PowerDesigner 的cdm文件
CREATE TABLE [dbo].[ProductAttributeDataType
[DataTypeId] [int] NOT NULL ,
[Description] [varchar] (30) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL
)
CREATE TABLE [dbo].[ProductAttributeListItem
[LookupListId] [int] NOT NULL ,
[ListItemId] [int] IDENTITY (1, 1) NOT NULL ,
[DisplayName] [varchar] (50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL
)
CREATE TABLE [dbo].[ProductAttributeLookupLi
[LookupListId] [int] IDENTITY (1, 1) NOT NULL ,
[Name] [varchar] (80) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL
)
CREATE TABLE [dbo].[ProductAttributeTemplate
[PATCategoryId] [int] IDENTITY (1, 1) NOT NULL ,
[Name] [varchar] (50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL ,
[DisplayName] [varchar] (255) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL
)
CREATE TABLE [dbo].[ProductAttributeTemplate
[AttributeTemplateId] [int] IDENTITY (1, 1) NOT NULL ,
[Name] [varchar] (50) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL ,
[DataType] [int] NOT NULL ,
[LookupListId] [int] NULL ,
[PATCategoryId] [int] NOT NULL ,
[CustomerHelp] [varchar] (4000) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ,
[DisplayName] [varchar] (255) COLLATE SQL_Latin1_General_CP1_CI_AS NULL
)
CREATE TABLE [dbo].[ProductAttributeValues] (
[ProductId] [int] NOT NULL ,
[AttributeTemplateId] [int] NOT NULL ,
[valueInt] [int] NULL ,
[valueStr] [varchar] (255) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ,
[valueMemo] [text] COLLATE SQL_Latin1_General_CP1_CI_AS NULL ,
[valueBool] [bit] NULL
)
CREATE TABLE [dbo].[ProductListItems] (
[ProductListId] [int] NOT NULL ,
[ProductId] [int] NOT NULL ,
[ItemDescription] [varchar] (80) COLLATE SQL_Latin1_General_CP1_CI_AS NULL ,
[DisplaySequence] [int] NOT NULL
)
不知道大家有没有看懂这些表之间的关系,这是一个产品目录的表,产品有不确定的属性,每个属性对应的数据类型也不一样,而且有的是用下拉列表选择的,有的是 是或否,有的是一段儿文字,这里用的就是数据模板来做的,这是里的一部分数据库
---------------------------------------------------------------------------------------------------------------------------------
以前有这样的一个需求,不考虑像京东或者淘宝这样分类下有子分类的情况,只考虑一层分类的情况下,可以随便添加分类,可以任意给商品添加属性,而不需要更改表的结构. 于是设计了一个这样的结构,实现还是可以实现,一直在用,但是在操作上比较麻烦,大家讨论下有没有更好的方式.
----------------------------- 以下是几个关联的对象 省去了 getter/setter 方法 ------------------
Field.java 属性
Java代码
public
class Field{ private Integer id; private String name; // 属性名称 }
ProductField.java 商品属性
Java代码
public
class ProductField{ private Integer id; private Field field; // 属性对象 private String value; // 属性值 这里的值不管是整数 小数 还是什么类型都是用 String 类型 }
Product.java 商品表
Java代码
public
class Product{ private Integer id; private String name; //商品名称 //根据商品 加载这个商品的所有属性 和属性值 private Set productFields = new HashSet();//商品属性集合 }
Type.java
Java代码
public
class Type{ private Integer id; private String name; //分类名称 //通过类型 可以加载这个类型下的所有商品 一种类型对应多种商品 //(暂时不考虑一种商品属于多种类型 例如手机属于电器类,也属于通讯类产品) private Set products = new HashSet(); }
----------------------
//表关系
Type
id name
1
3
4
Product
id
1
2
3
4
Fields
id name
1
2
3
...
ProductFields
id pdctid
1
2
3
4
5
--加载的测试数据
+++++++++ 商品信息 ++++++++
Name:Sony
价格 -
2000.00 型号 - YY-1939
名称 - 锁你牌手机
我要补充的是,当商品越来越多的时候,属性的增加也是自然的,有肯能属性增加到1000种,
那么我在后台管理 新增加一个商品,给它添加属性时,这时就需要从已经存在的属性中选出
它所需要的那么10种或者20种属性。
我的想法是,程序处理中:
1.在页面输出可选择的属性时按属性名称排序,这样可能选择快一些。
2.提供属性搜索,看数据库中有没有这么一属性,如果有直接使用,如果没有就添加
3.修改此数据库表,属性应该和大的类型相关联,作为常用属性。 次要属性可以从后续的属性列表中选择。
动态列性能上确实可能会有点问题。比如你要统计:红色的手机的一个月销售额就需要至少在四个表(类型、产品、属性、销售)进行联合查询。
我以前遇到类似问题,而且时间上不允许更改设计了,当时只是采取了一些简单的处理方式,比如针对需要的统计生成中间表,对库进行索引优化,根据时间进行分表等等。不过我个人感觉出问题的地方往往是一些特定统计,如果你能确定或基本上确定最终这些表的统计查询的方式,我觉得问题不大。你可以预估下数据量,假设半年后的运营, 类型、产品、属性、销售等数据大概是多少,联合查询的总记录数是多少。如果这个数据比较恐怖,那你再可以考虑更换其他方式。
复杂商品的分类,类似淘宝的分类
1.每类商品有无限级分类
2.每个商品可能会有交叉分类
3.每类商品的扩展属性不一样
比如:
夹克的扩展属性为
款式: 拉链夹克 风格: 休闲 品牌: other/其它 适合季节: 春秋 尺码: M L 颜色: 其它颜色 质地: 纯棉
主板的扩展属性为
品牌: 微星/MSI 类型: Socket478 芯片组: Intel 845 平台类型: Intel平台 宝贝成色: 8成新
这些扩展属性都会动态的变化
那么问题来了:
1.全文搜索如何合理建立?
2.可能后台扩展属性表是否需要动态建立?
3.如果单件商品属于交叉分类的话,查询结果记录重复是否需要?
4.高效的无限级分类算法大家可否指点一二,这个困惑了我很久了?
不求完整解决,给个思路也成
每个商品都是一个xml文件 每个xml文件有一个ID 每个xml文件可以采用这样的结构
<名称/>
<属性/>
<属性/>
......
当检索商品的时候 比如用Socket478芯片组检索 就检索出所有含有Socket478芯片组属性节点的xml文件. 用一个xql语句就可以搞定. 返回的结果是xml文件 可以用xsl进行处理 然后用css显示
这类问题(无限级别分类,可以交叉分类)很难。
正是现代 tag,分类时代的热点问题。我也考虑调查了很久。
如果解决得好,就可以被收购了。
xml 解决起来确实比 relation table 容易一些。xml全文检索也比较容易做。
我想,winterwolf会跳出来,终于等到了。
不过,xml也有一些限制。如果能有一种专门描述这类问题的数据结构就好了。
我想到过几种数据结构。不过都没有想透。
Multiple Key Hashmap。多维数组。等。
xml确实是一种解决的办法,tianxinet的子表方法有点繁琐了,扩展属性有很多表也带来了维护的困难性了。。如果像淘宝的商品分类那样的话,你的子表数量是很惊人的。。。。
继续关注中
---------------------------------------------------------------------------------------------------------------------------------
前几天有人问了我一个这样的问题,因为时间的关系,我当时尝试做了几种回答,比如将产品先分大类,为每个大类设计一个产品表,在产品表中包括该类的基本属性,并预留一些字段作为扩展属性,对于同一大类不同的产品,考虑增加扩展表。不过这个答案似乎没有得到认可。认真一想也是,如果这样,表改有多少,查询结构又该多复杂。
beyond_dream
方案一。
就一个产品表 product,然后这个表里包括所有的产品属性,每个属性用一个字段表示。
方案二。
还是只用一个产品表 product 。
与方案一不同的是,私有属性设置为一个字段 Private_Attribute ,
然后每个产品的多个私有属性都放这个字段里,并且用一个分隔符号隔开
比如书籍,就是 它在 Private_Attribute 字段里 的表示就是 :
出版社||||作者||||出版日期
方案三;
产品表 + 私有属性表 + 私有属性值 表
产品表 里 就包括一些产品的公共属性
私有属性表 里 设置私有属性的名称 ,比如出版社 、作者 、出版日期
私有属性值 表 里就是 每个产品 私有属性的值
例如:
产品表:
product_id = 1 ; product_name =《ajax实践》
私有属性表:
Attribute_id = 1 ; Attribute_name = 出版社
Attribute_id = 2 ; Attribute_name = 作者
私有属性值表:
id = 1 ; product_id = 1 ; Attribute_id = 1 ; Attribute_value = 清华出版社
id = 2 ; product_id = 1 ; Attribute_id = 2 ; Attribute_value = 老外
方案四;
每个不同类型的产品单独设计一个数据库,比如一个书籍的数据表 product_book,一个MP3的数据表 product_mp3
1. 对产品按照大类进行区分,每个大类有一个产品表。产品表有该大类产品最基本的关键属性信息(应该控制在十个以内,这些属性,也被用作关键字查询索引),而接下来,又有一些预定义的扩展属性(命名如customized1, customized2,等等),这些扩展属性有一个重要的前提,就是它们的属性值都是列表选择的,而不是自由输入的(当然这些选择项是可以在另外的表中定义的),这些属性是用作在详细的高级查询中使用的,使用选择而不是自由输入第一是可以提高索引效率,第二是可以避免因为字符差错引起的歧义,第三是可以使用区间值。每个不同的产品小类有不同的customized定义。最后有再有几个字段,则存放其他的由客户特性带来的属性值,但是是以xml的形式存放,可以方便使用XPATH来提升效率。
http://raylinn.javaeye.com/admin/blogs/260407
ms 和我以前想的这个有点像。。。 固定的属性和模糊的介绍都通过lunce来搜索。。
问题补充
我也是想用多个表,多个表有点不好的地方,就是如果用户在A表买了一件产品,又在B表买了一件产品,那么到最后统计用户买过的产品时,虽然可以从下订单那个表读出来,但是感觉有点乱~~~
问题补充:
产品类别表(类别id,名称,...)
产品表(产品id,名称,规格,...)
产品属性表(产品属性id,产品id,属性id,值,...)
这种方法行不行?
问题补充:
产品表(产品id,名称,规格,...)
产品属性表(产品属性id,产品id,属性id,值,...)
就说这两个表吧,当插入一件产品的时候,属性应该是直接去到产品表的,如果加了一个属性表,那么插入的时候,
难道可以插入一个产品id在产品表,然后又插入属性在产品属性表吗?
方案一(推荐):在商品类型已知的情况下,为每类商品定制一个类。class 手机,class 笔记本
方案二:如果商品类型位置,那就用一个通用的商品类,里面放个property
方案一:商品属性定义表(存放xml格式定义),商品表(基本字段+属性定义ID+属性xml描述),有了xml格式和xml描述,其他的xml数据解析和前台展示就可通用处理了,细节你可以再看看。
方案二:如上。
只是打开想了想,不知道能否帮到你

 感谢支持与鼓励~
感谢支持与鼓励~